
Did you know that if you deindex or delete some of your pages, it can actually help your SEO?
Index bloat, also known as over-indexing, can really hurt your SEO. It’s great to have all the important pages indexed, but if you have too many, it can really hurt your rankings. In this blog post, we’ll look at what index bloat is, its side effects, and how to identify & fix it.
What Is Index Bloat In SEO?
Index bloat refers to a situation where Google crawlers index excessively low-quality or irrelevant pages on a website. This can happen for various reasons, such as poor website architecture, URL structures, duplicate content, and automatically generated pages. When a Google bot crawls and indexes a specific website, it aims to present its users with the best and most relevant content. But index bloat SEO issues can reduce a website’s authority and relevance ranking in search engine results.
Index bloat issue is most common on retail sites. Many ecommerce sites have filters or widgets that let you quickly find products that match what you’re looking for. But filters like “color” or “ customer reviews” don’t usually create new pages once you’ve chosen the correct parameters.
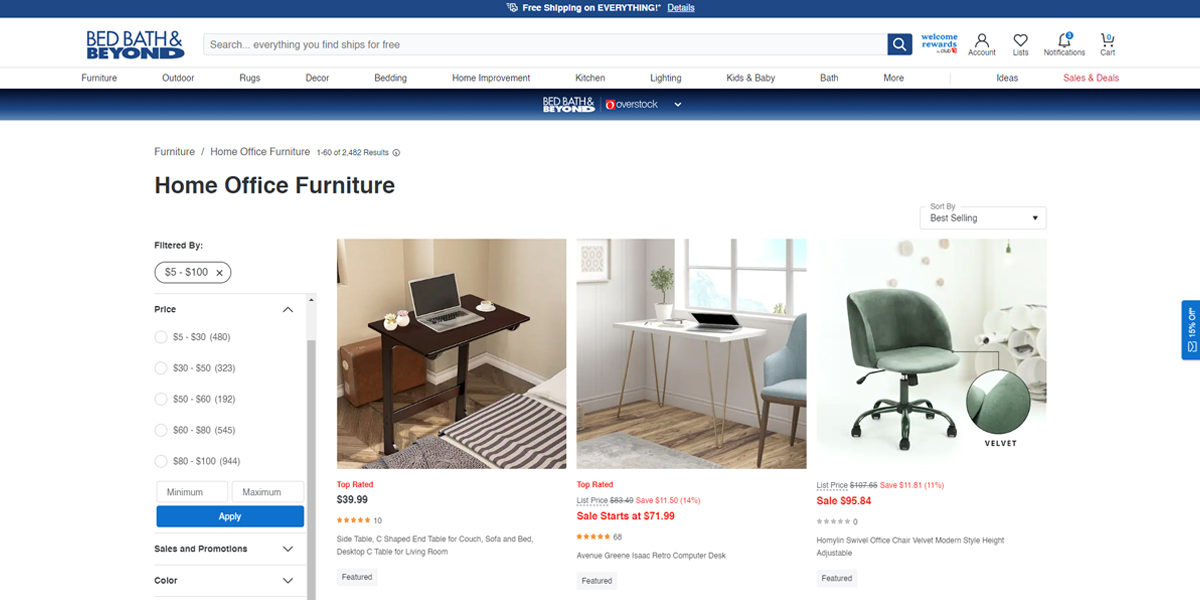
When Google crawls a website, it follows all the links and tabs on the page, including filters, which means it may end up indexing thousands of pages that don’t add anything new to Google or users.
Google’s Opinion on Index Bloat
Google officially disagrees that index bloat is a real issue. In the recent episode of the ‘Search Off The Record’ podcast, Google’s Search Relations team addresses questions about webpage indexing. John Mueller, Google Search Advocate, rejects the idea of index bloat.
However, the SEO community feels different. Many SEO experts like Brian Dean, founder of Backlinko, say this is very much real & can quietly kill your SEO without you even knowing it.

How Does Index Bloat Impact SEO Performance?
If you’re dealing with an index bloat issue, it can slow down your processing and stop your data from indexing properly. It can confuse search engines. When search engines find your site with index bloat, they can’t determine which page is most important to searchers and might show irrelevant results – something Google wants to avoid as much as possible.
It can also run out of crawl budget. The number of URLs that Googlebot crawls during each visit to each website is known as the crawl budget. When the crawl budget reaches the next domain, Googlebot will crawl that domain. However, index bloat means that pages more relevant to your site will not be crawled, as the ” crawl budget ” is used to index irrelevant pages.
As a result of index bloat, your website’s high-quality, relevant content may remain unindexed, and duplicate pages may be indexed. These low-quality, duplicate pages are not likely to rank for users’ search queries. See below; Google states that it focuses on providing users with the most relevant, reliable information, which is why Google may choose to serve high-quality, duplicate content from other websites.
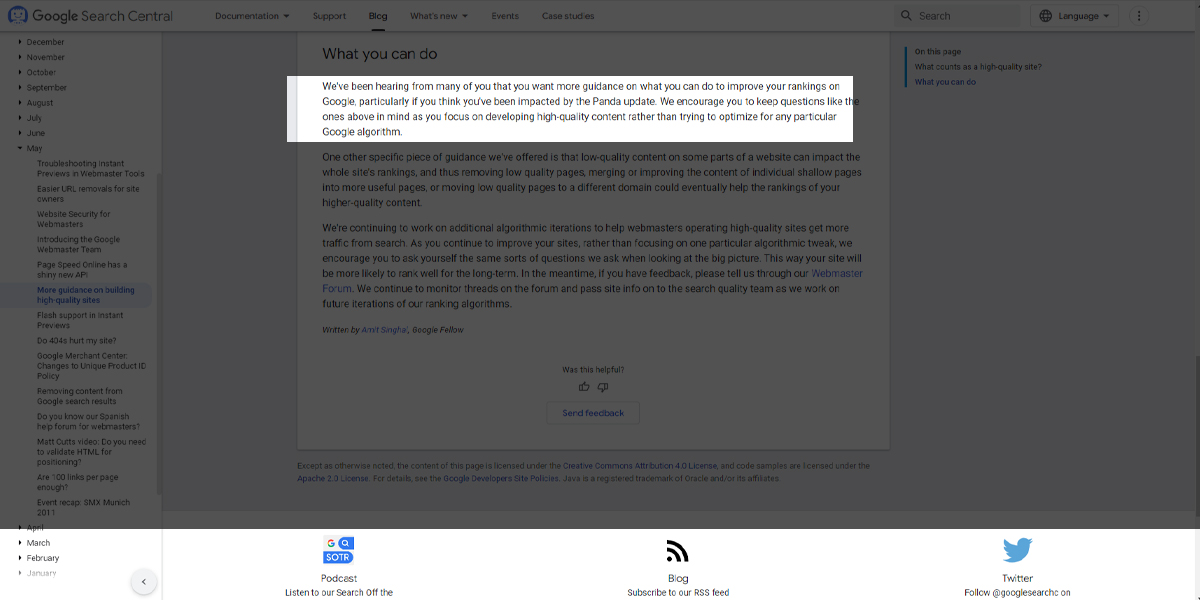
This could result in a drop in rankings for your website. And, before you know it, it can spiral out of control, decreasing traffic and conversions.

Remember, Google comes to a website with a set amount of crawl budget. If you let them waste that on duplicate and junk pages, you risk letting your traffic and rankings suffer while your indexing becomes bloated. Your crawl rate – which correlates with traffic levels – will be reduced.
Why Does Index Bloat Issue Happen?
Here are the primary reasons why index bloat SEO issue occurs:
Pagination
Pagination is one of the most popular ways to display content in smaller, easier-to-digest chunks. It’s most commonly found in e-commerce product descriptions, business blog post archives, search results, and other forms of content that need multiple pages to display.

Although pagination is a great UX feature, it can cause index bloat if not managed correctly. Pagination often leads to multiple URLs that show the same or similar content on different pages. Most paginated pages have only minor changes, such as a change in page number or an offset.
However, search engines treat every paginated page like a single URL and try to index all paginated pages. This can result in index bloat if a website has too many paginated pages. Search engines spend a significant amount of the crawl budget on indexing paginated pages on their crawlers. However, this may also result in Google crawlers overlooking other important and valuable pages on your website.
Also Read: Why Is Responsive Web Design Important?
Duplicate Content
When a search engine finds duplicate content, it tries to find the most appropriate version to display in the search results. Search engines need to know which version to show higher in the search results if they can’t find a clear preference. If a search engine can’t tell which version to display, it can spread the ranking signal across duplicate pages and reduce the overall ranking power of your content.
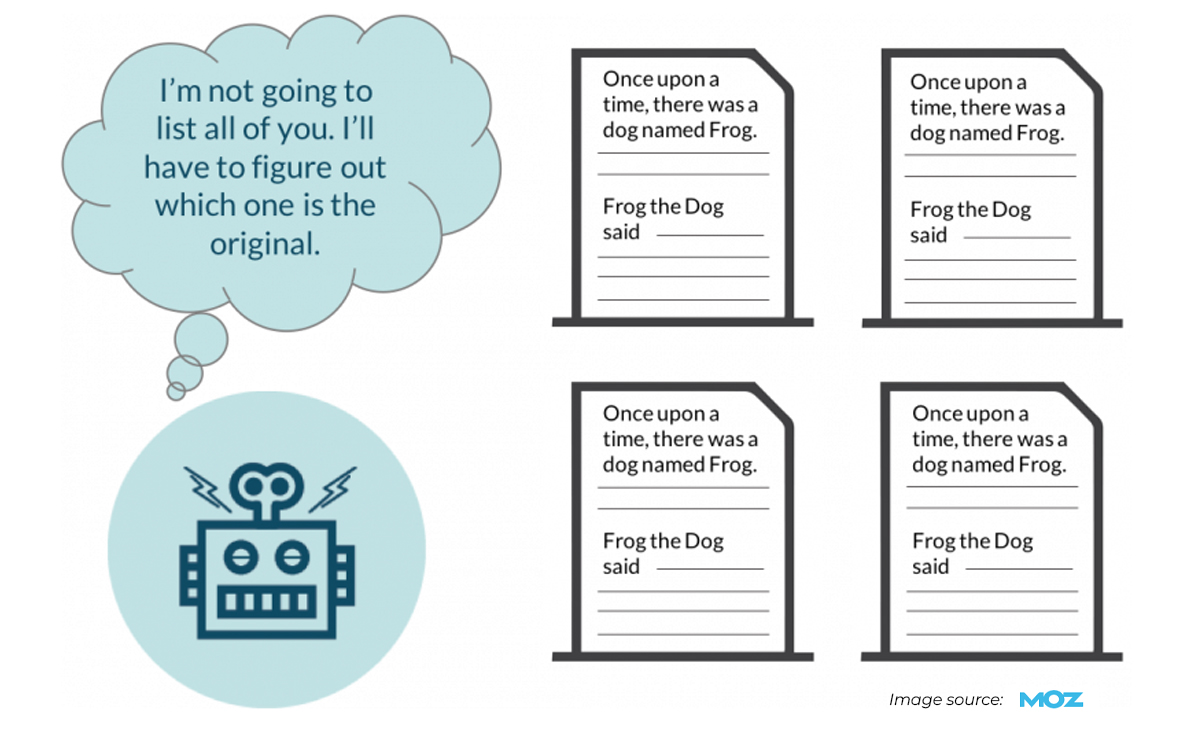
When search engine bots crawl a website to find and index content, duplicate content may be found in the crawl. Each instance of duplicate content is indexed as a separate page. This leads to duplicate URL pointing and eventually causes index bloat issues. Sometimes, a search engine interprets duplicate content as manipulating search rankings or poor-quality content. Consequently, the website may be penalized by decreasing its visibility in the search results or being excluded from the search results altogether, wasting all your content amplification efforts.
Missing Robot.txt File
The robots.txt file is a text file located at the root of a website’s domain and is used to communicate with web crawlers. It provides instructions to these bots on which website pages or sections should be crawled & indexed and which ones should be excluded from indexing. When the robots.txt file is missing, search engine bots may crawl and index pages that should ideally be kept out of their index, leading to index bloat.
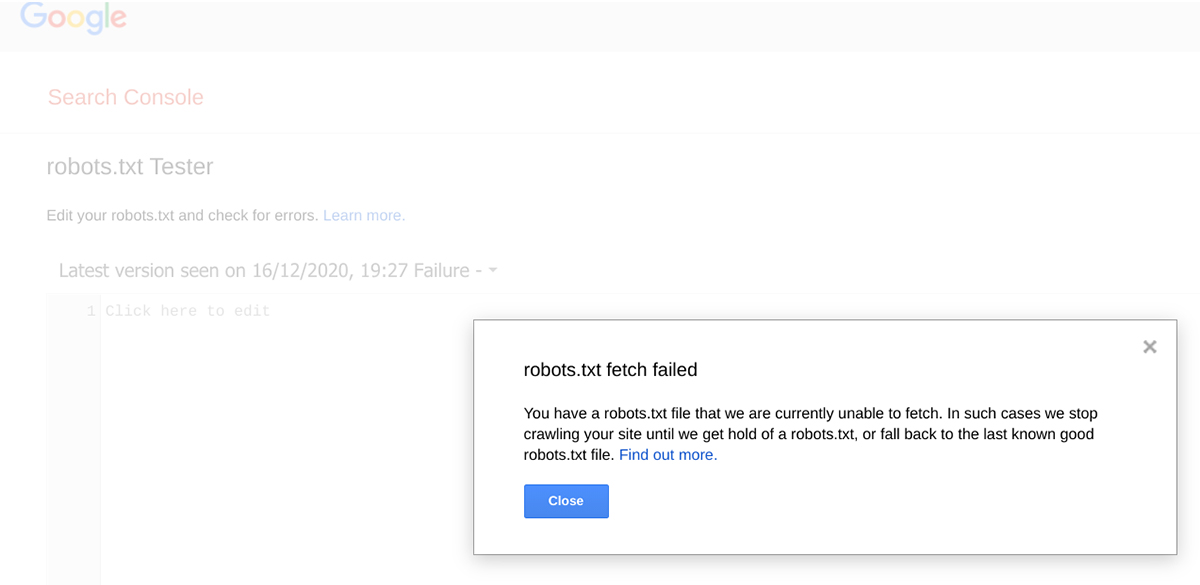
If the robots.txt file is missing entirely, search engine bots may crawl and index every page they can find on the website. This can lead to the indexing of low-quality, irrelevant, or sensitive pages that were not meant to be visible in search results, resulting in index bloat.
Missing robot.txt files may also not allow search engines to crawl orphaned pages on a site that are not linked to other site pages. They may remain unindexed and inaccessible to search engine users, causing a poor user experience.
How To Identify Index Bloat Issue?
To identify index bloat issues, it is necessary to analyze the indexed pages to determine whether many pages of poor quality, irrelevant or duplicate pages should not be indexed. The GSC report is a quick way to figure out which pages are causing index bloat issues. Look at the examples of URLs that are indexed but haven’t been included in your sitemap.
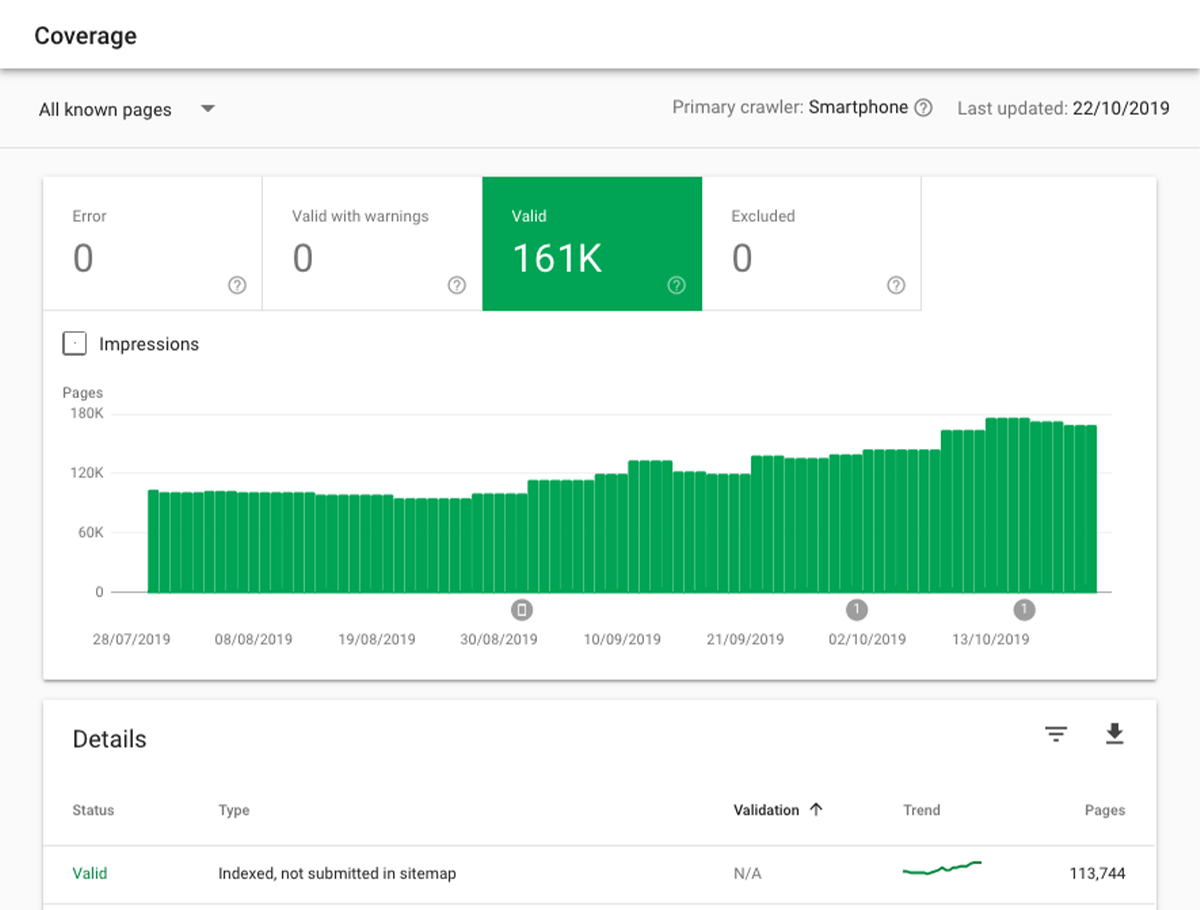
You can use the search engine operator tool to check how many pages from your website are currently indexed by search engine bots. But with so many URLs to keep track of, it can take time to figure out which ones are actually tracked by search engines.
Here is the comprehensive guide you can follow to see whether your website is facing an index bloat issue or not.
Step 1: Estimate the Total Indexed Pages
Begin by estimating the total number of indexed pages on your website. Consider the number of products, categories, blog posts, and support pages. This estimation will give you an overview of the scale of your indexed content.
Step 2: Create a URL List from Your Sitemap
Your XML sitemap should contain all the URLs you wish to be indexed. Extract the URLs from your sitemap and create a valid list. There are tools available to assist you in this process.
Step 3: Download Published URLs
For WordPress users, plugins like “Export All URLs” lets you download a CSV file containing all published pages. This file will supplement your URL list.
Step 4: Run a Site Search Query
Conduct a site search query (site:website.com) on your domain. Analyze the SERPs to get an estimated count of indexed URLs. Alternatively, consider using specialized tools for URL scraping.
Step 5: Use Google Search Console Page Indexing Report
Google Search Console provides relevant information on how many valid pages are indexed by Google. Download the report as a CSV for further analysis.
Step 6: Analyze Log Files
Log files offer insights into which pages are frequently visited, even those you weren’t aware of. Request your hosting provider for log files or access them directly to identify underperforming pages.
Step 7: Google Analytics 4
Export a list of URLs that generated page views in the last year from Google Analytics 4. Utilize “Reports → Pages and Screens” with “Page Path and Screen Class” as your primary dimensions. Export the data as a CSV.
Step 8: Consolidate URLs and Remove Duplicates
Merge all collected URLs and remove any duplicates or URLs with parameters. This will give you a refined list of indexed pages to work with.
Step 9: Employ a Site Crawling Tool
Use a site crawling tool like Screaming Frog and integrate it with Google Analytics, Google Search Console, and Ahrefs. Extract traffic, click, and backlink data for comprehensive website analysis.
This data can then be used to identify which URLs on the website are not performing as expected — and therefore do not merit a place on the website.
How Do You Fix Index Bloat SEO Issues?
Now that we have understood how to identify all the pages causing index bloat. The next and crucial step is to fix the problem.
Remove Internal Links
Review your website’s internal linking structure and identify low-quality, redundant, or no longer-needed pages. Remove internal links pointing to such pages to discourage search engine bots from crawling and indexing them. Ensure important pages receive more internal link juice to strengthen indexing and rankings. Use “nofollow” tags on links pointing to pages you want to command search engines not to do indexing.
Read also: What is Cross-Linking in SEO & How It Improves Your Ranking?
Update or Install robots.txt
Check your website’s robots.txt file to ensure it is appropriately configured to exclude irrelevant or duplicate pages from search engine crawlers. Update the file to include directories or pages that should not be indexed.
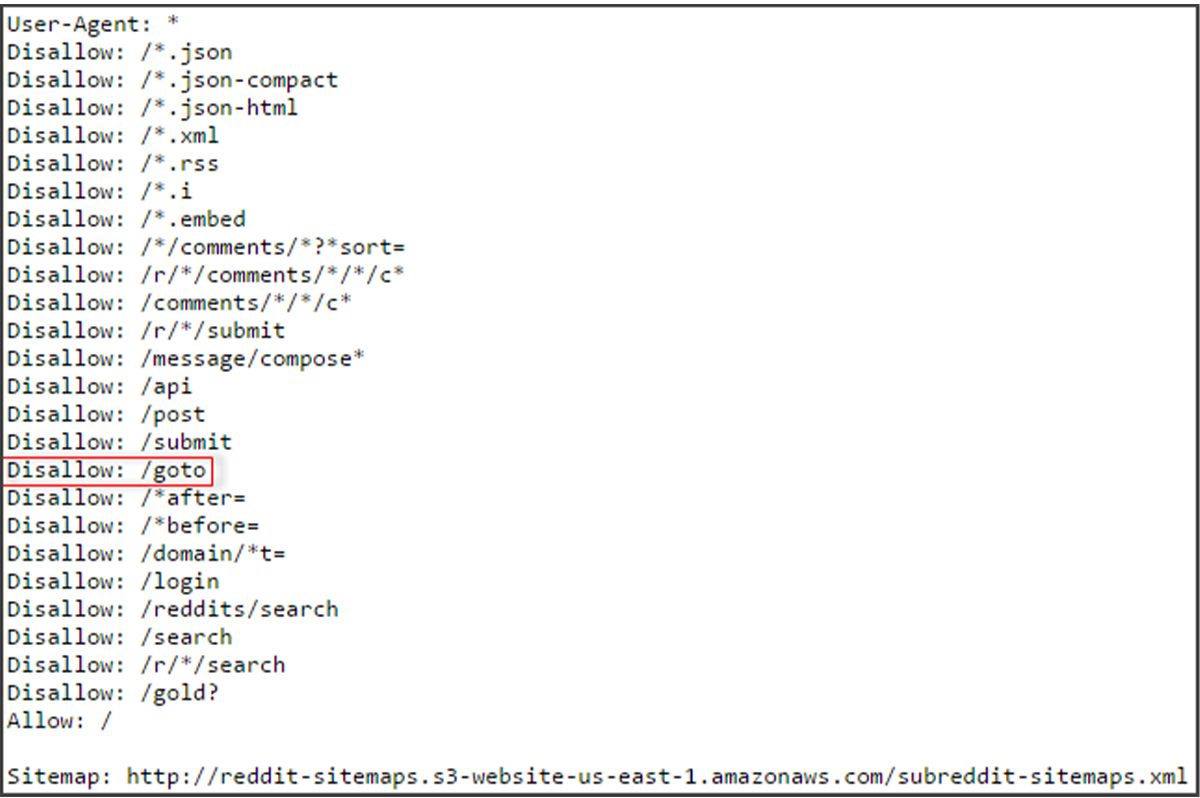
Test the robots.txt file using Google Search Console’s robots.txt tester to verify its effectiveness.
Use Meta Robots Tags and X Robots
Utilize meta robots tags or X-Robots-Tag HTTP headers to instruct search engines not to index specific pages. Utilize “noindex” tags on particular pages that search engines should not index. Use “noarchive” to prevent search engines from displaying cached versions of your pages.

Use code <meta name=”robots” content=”noindex, follow”> to specify crawlers that they shouldn’t index these pages, but they can follow the links on these pages. This ensures that Google can index the other pages via those links but not index the page itself.
301 Redirects
If your website has multiple URLs with the same or similar content, implement 301 redirects to the preferred canonical version of the page.
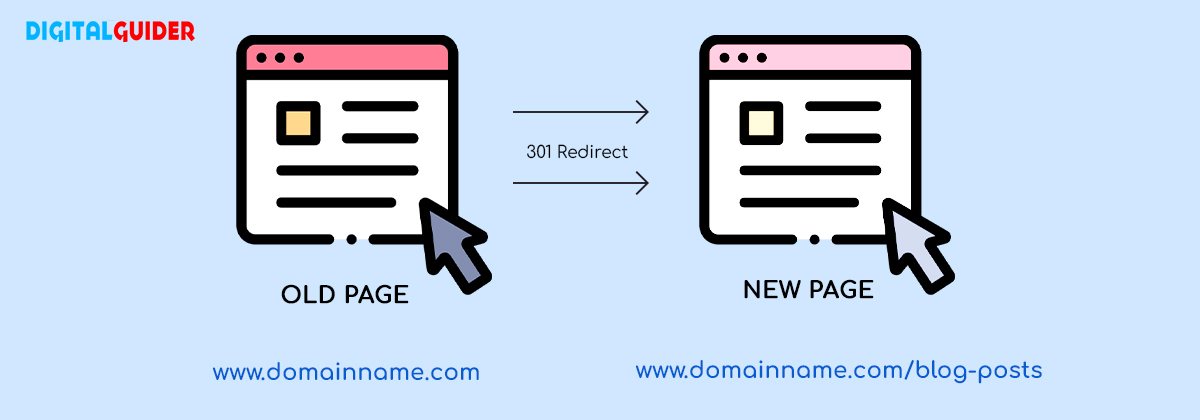
This will consolidate link equity and ranking signals to the canonical URL, reducing index bloat from duplicate pages.
Recommended Blog: Backlinks vs Referring Domains: Everything You Need to Know
Add Canonical Tags
Canonical tags inform search engines about the primary page to index, avoiding index bloat from duplicate pages. Add canonical tags pointing to the preferred canonical version for pages with similar content. Go to the header section of the duplicate pages and add the code: <link rel=” canonical” href=”<URL of the original page>
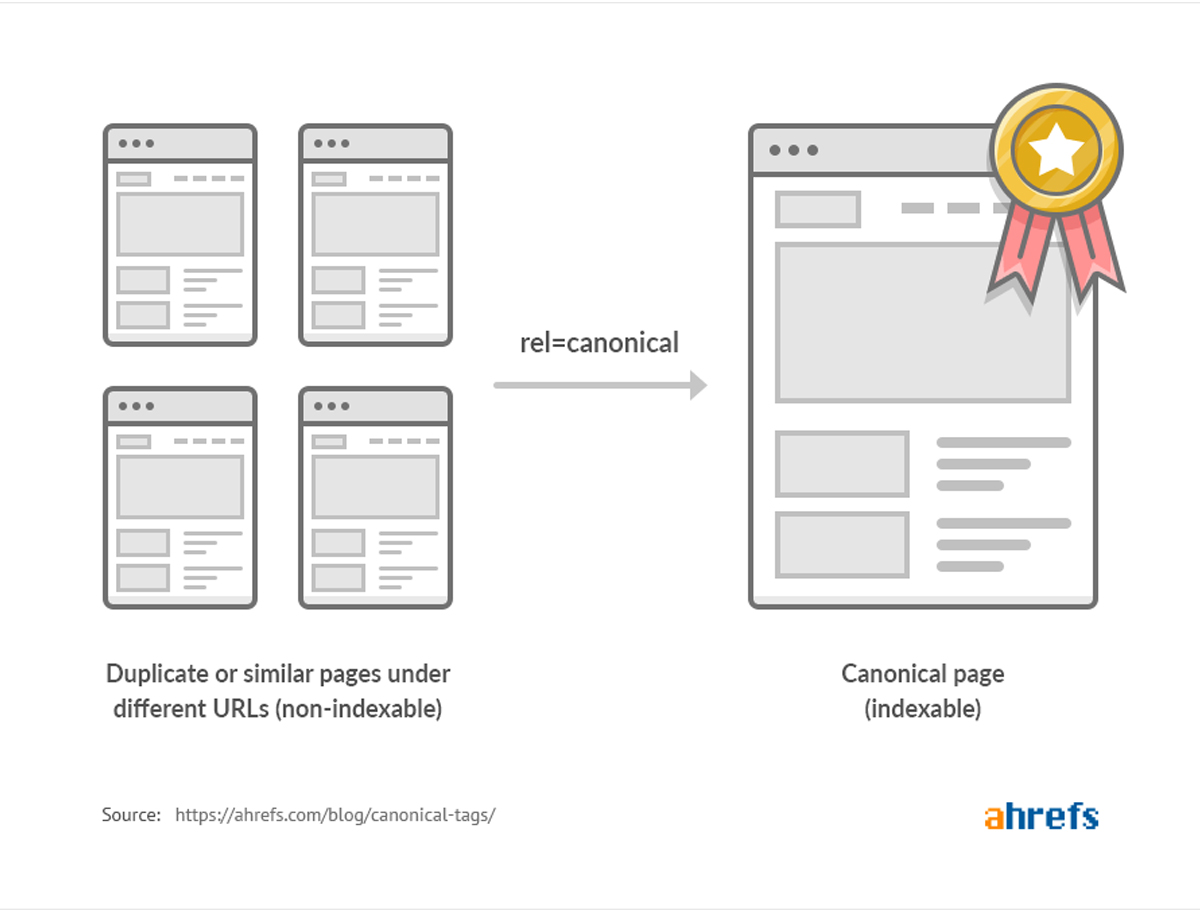
When Googlebot comes across a page with a “canonical” tag, it’ll know that it’s not the original version of the page, so that it won’t index it. Not only that, but a “canonical tag” also consolidates the link equity from those pages and passes it on to the main page.
Noindex Tags
Implement “noindex” meta tags on pages you want to exclude from search engine indexes. This direct instruction to search engines prevents them from indexing those pages, reducing index bloat.
Implement Pagination Properly
If your website has paginated content (e.g., product listings, article archives), use rel=”next” and rel=”prev” tags to signal proper pagination to search engines. This prevents them from indexing each paginated page separately, avoiding index bloat.
Remove / Consolidate Pages
Conduct a thorough content audit and identify low-quality or underperforming pages. Improve their content or consider removing them entirely to reduce index bloat. Additionally, consolidate similar content into one comprehensive page to avoid duplication.
Use URL Removal Tool
If you are confident that pages were inadvertently indexed and should not appear in search results, use Google Search Console’s URL removal tool (or similar tools for other search engines) to request their removal from the index.
Also Read: How To Disavow Toxic Backlinks?
Wrapping Up
Index bloat is one of the most common issues that affect a website’s performance in search engine results pages (SERPs) and user experience (UX). When search engines index too many pages that are not relevant, valuable content is buried. This results in a dilution of rankings and a waste of crawl resources.
However, understanding the causes and applying effective technical solutions can help overall SEO performance.
To tackle index bloat effectively, you must implement several technical measures. By following above discussed steps, such as,
- Remove Internal Links
- Update or Install robots.txt.
- Use Meta Robots Tags and X Robot
- 301 Redirects
- Add Canonical Tags
- Implement Pagination Properly
- Remove or Consolidate Pages
- Remove Indexed Pages With URL Removal Tool
- Implement Noindex Tags
Now that you understand how to identify and fix index bloat on your site, it is time to remove it. However, it is recommended that you allow your technical SEO specialist to apply the solutions mentioned above. If you make a mistake, index bloat may also affect the indexing of important pages on your site. You can consult our SEO experts if you need help resolving index bloat issues.






